文件系统的IO操作
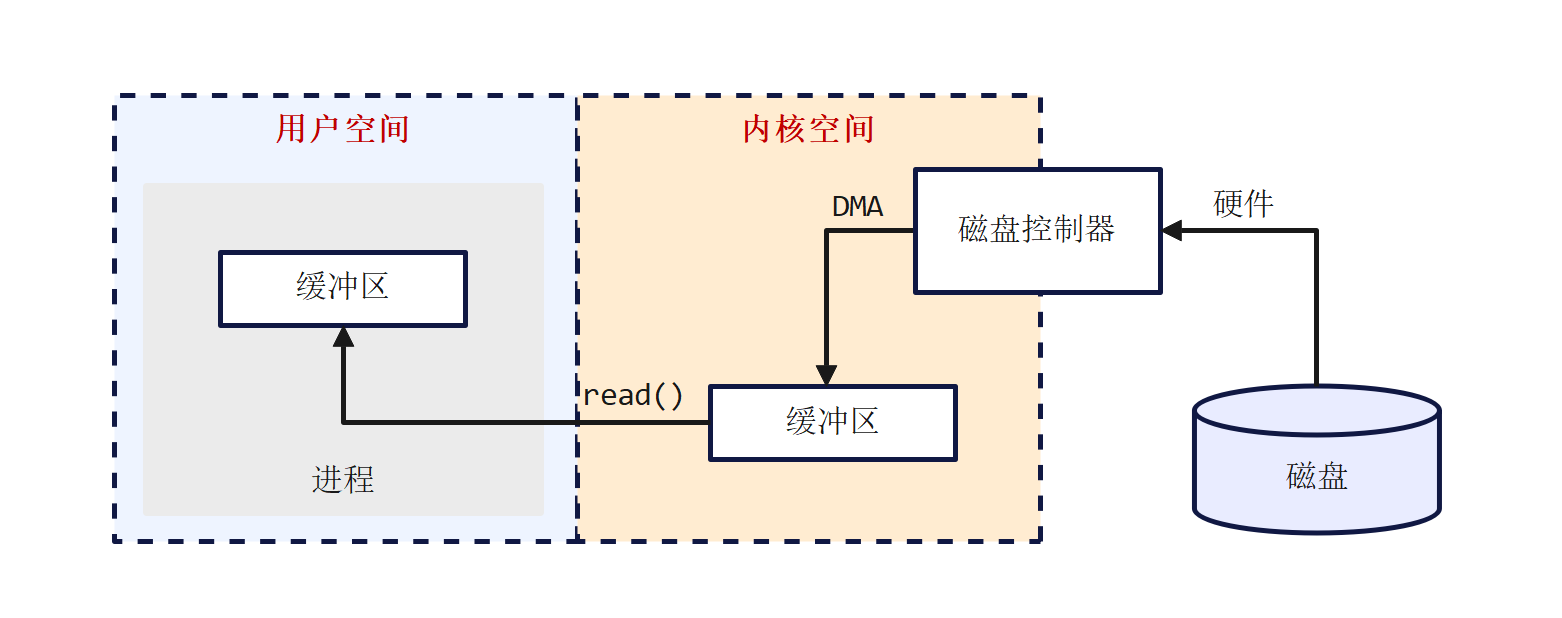
在Linux中,以及大多数现代操作系统中,文件系统的IO操作通常是通过缓存IO来完成的。这种设计主要是为了提高IO性能,减少直接对磁盘的访问次数,并通过页缓存(page cache)来缓存热点数据,从而提高数据的访问速度。
详细讨论一下这两个阶段:
数据准备阶段:
- 当应用程序发起一个读或写请求时,该请求首先被送到操作系统内核。
- 内核查看页缓存,看看所需的数据是否已经在缓存中。如果是读操作并且数据已经在缓存中,那么内核可以直接从缓存中读取数据,而不必访问磁盘。这称为“缓存命中”。
- 如果数据不在缓存中(缓存未命中),那么内核会向磁盘控制器发送一个请求来获取数据。
- 一旦磁盘控制器读取了数据,这些数据会被放入页缓存中,然后内核会将这些数据传递给应用程序。
内核空间复制回用户进程缓冲区阶段:
- 当内核从页缓存中获取数据后,这些数据首先被放置在内核空间的缓冲区中。
- 由于应用程序运行在用户空间,而内核处理IO操作在内核空间,因此数据需要从一个空间复制到另一个空间。
- 这涉及到上下文切换,即从内核模式切换到用户模式,并将数据从内核缓冲区拷贝到应用程序的缓冲区。
- 这一步的复制操作会增加CPU和内存的开销。
为什么磁盘控制器不能直接将数据发送到应用程序的地址空间,因为应用程序通常不能直接操作底层硬件。这是出于安全和稳定性的考虑。操作系统内核作为硬件和应用程序之间的中间层,负责管理和协调硬件资源,确保应用程序的合法和有效访问。
为了减少这种开销,现代操作系统和硬件提供了各种优化技术,如直接I/O(DIO)、写时复制(Copy-on-Write)等,以及在硬件层面上的DMA(Direct Memory Access)技术,这些技术可以减少内核和用户空间之间的数据复制,提高IO性能。
一、阻塞I/O(BIO)
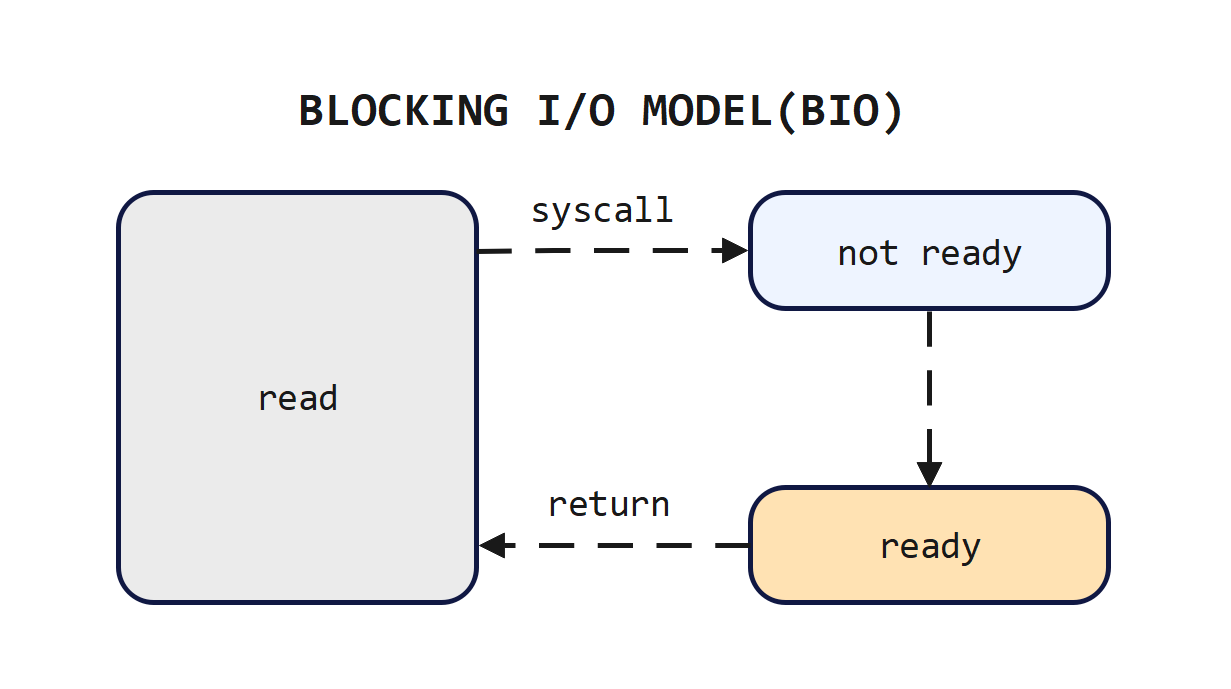
在这种模型中,当进程或线程调用一个I/O函数(如recvfrom)时,它会一直等待直到该操作完成或发生错误。在等待期间,进程或线程会被阻塞,即它不会执行任何其他操作,也不会消耗CPU资源,直到I/O操作完成。
阻塞式I/O模型的主要优点是实现简单,因为程序员不需要处理复杂的状态变化和异步事件。此外,对于简单的、低并发的应用程序来说,阻塞式I/O通常足够使用,因为每个请求通常很快就能得到处理。
然而,阻塞式I/O模型在处理高并发网络应用时存在明显的缺点:
- 系统开销大:由于每个I/O操作都需要阻塞一个进程或线程,当并发请求量很大时,需要大量的进程或线程来处理这些请求,这会导致系统资源(如内存和CPU)的过度消耗。
- 响应性能问题:在高并发场景下,由于大量的进程或线程在等待I/O操作,CPU可能会花费大量的时间在进程切换上,而不是在处理实际的数据,这降低了系统的整体性能。
- 可扩展性差:随着并发请求的增加,需要不断增加进程或线程的数量,这可能会导致系统资源耗尽,限制了系统的可扩展性。
为了解决这些问题,人们开发了多种I/O模型,如I/O多路复用(如select、poll、epoll)、异步I/O(如Linux的aio_read和aio_write)等,这些模型旨在提高系统的并发处理能力和响应性能。这些模型通过不同的机制,允许进程或线程在等待I/O操作完成时继续执行其他任务,从而提高了系统的整体性能和可扩展性。
二、非阻塞I/O(NIO)

非阻塞式I/O模型(Non-blocking I/O)允许进程发起I/O操作后继续执行其他任务,而不是等待I/O操作完成。如果I/O操作可以立即完成(例如,内核缓冲区中有数据可读),则I/O操作会立即返回数据。如果I/O操作不能立即完成(例如,内核缓冲区中没有数据可读),则调用会立即返回一个错误,通常是EAGAIN或EWOULDBLOCK,告诉进程数据尚未准备好。
非阻塞式I/O模型的特点如下:
- 非阻塞:进程不会因为I/O操作而阻塞,可以立即返回并继续执行其他任务。
- CPU资源消耗:由于进程需要轮询(poll)来检查I/O操作是否完成,这可能导致大量的CPU资源被消耗在轮询上,而不是在处理实际的数据上。
- 实现难度:相比阻塞式I/O,非阻塞式I/O模型的实现要复杂得多,因为程序员需要处理部分完成的I/O操作、错误检查以及轮询的逻辑。
- 适用场景:非阻塞式I/O模型适用于并发量较小且不需要及时响应的网络应用开发。在并发量大的场景下,由于CPU资源的消耗和轮询的开销,非阻塞式I/O可能不是最佳选择。
然而,值得注意的是,尽管非阻塞式I/O模型在并发量较小的场景下表现良好,但它在处理大量并发连接时可能不是最有效的解决方案。在这种情况下,更高级的I/O模型(如I/O多路复用或异步I/O)可能更为合适。这些模型通过更有效的利用系统资源和减少CPU的轮询开销,提供了更高的并发处理能力和更好的性能。
三、信号驱动I/O
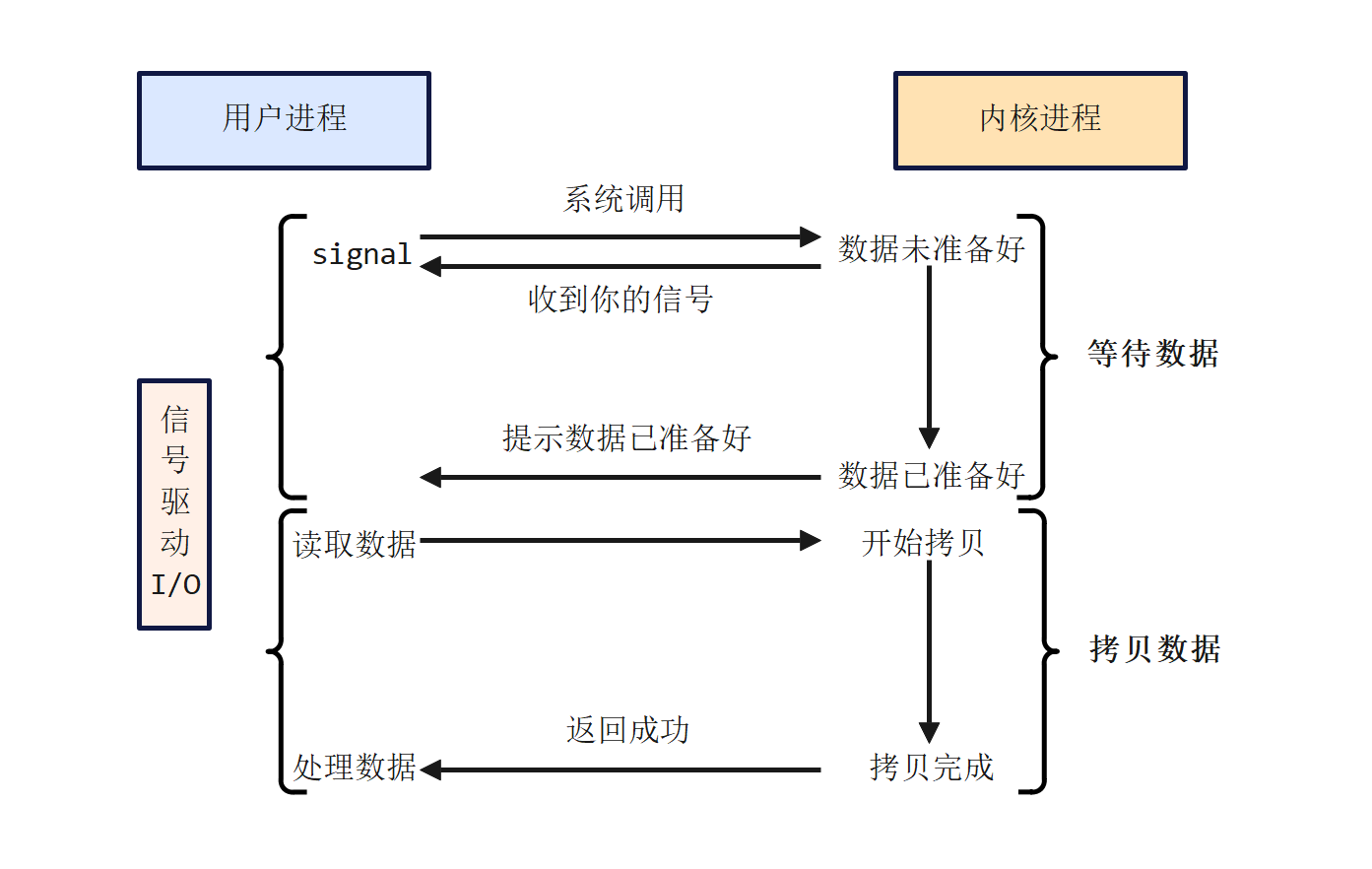
信号驱动I/O是一种网络I/O模型,它允许进程预先告知内核,在某个描述符上发生事件时,内核应使用信号通知相关进程。这种模型与异步I/O有所不同,异步I/O通常定义为进程执行I/O系统调用告知内核启动某个I/O操作,内核启动I/O操作后立即返回到进程中,进程在I/O操作发生期间继续执行,当操作完成或遇到错误时,内核以进程在I/O系统调用中指定的某种方式通知进程。
在信号驱动I/O模型中,当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。当数据报准备好读取时,内核就为该进程产生一个SIGIO信号。随后既可以在信号处理函数中调用read读取数据报,并通知主循环数据已准备好待处理,也可以立即通知主循环,让它来读取数据报。这种模型的优势在于等待数据报到达期间,进程可以继续执行,不被阻塞。
为了让套接字描述符可以工作于信号驱动I/O模式,应用进程必须完成以下三个步骤:
- 注册SIGIO信号处理程序。这可以通过sigaction系统调用完成,用于在信号发生时执行特定的函数。
- 使用fcntl的F_SETOWN命令设置套接字所有者。这将指定接收SIGIO信号的进程或进程组。
- 使用fcntl的F_SETFL命令,置O_ASYNC标志,允许套接字信号驱动I/O。这将使套接字进入信号驱动I/O模式,当数据准备好时,内核将向进程发送SIGIO信号。
需要注意的是,在使用信号驱动I/O时,因为信号是异步的,所以需要谨慎处理并发访问和数据一致性问题。此外,由于信号的处理可能会打断进程的正常执行流程,因此需要注意信号处理函数的设计和实现,以避免对进程状态的影响。
四、异步IO
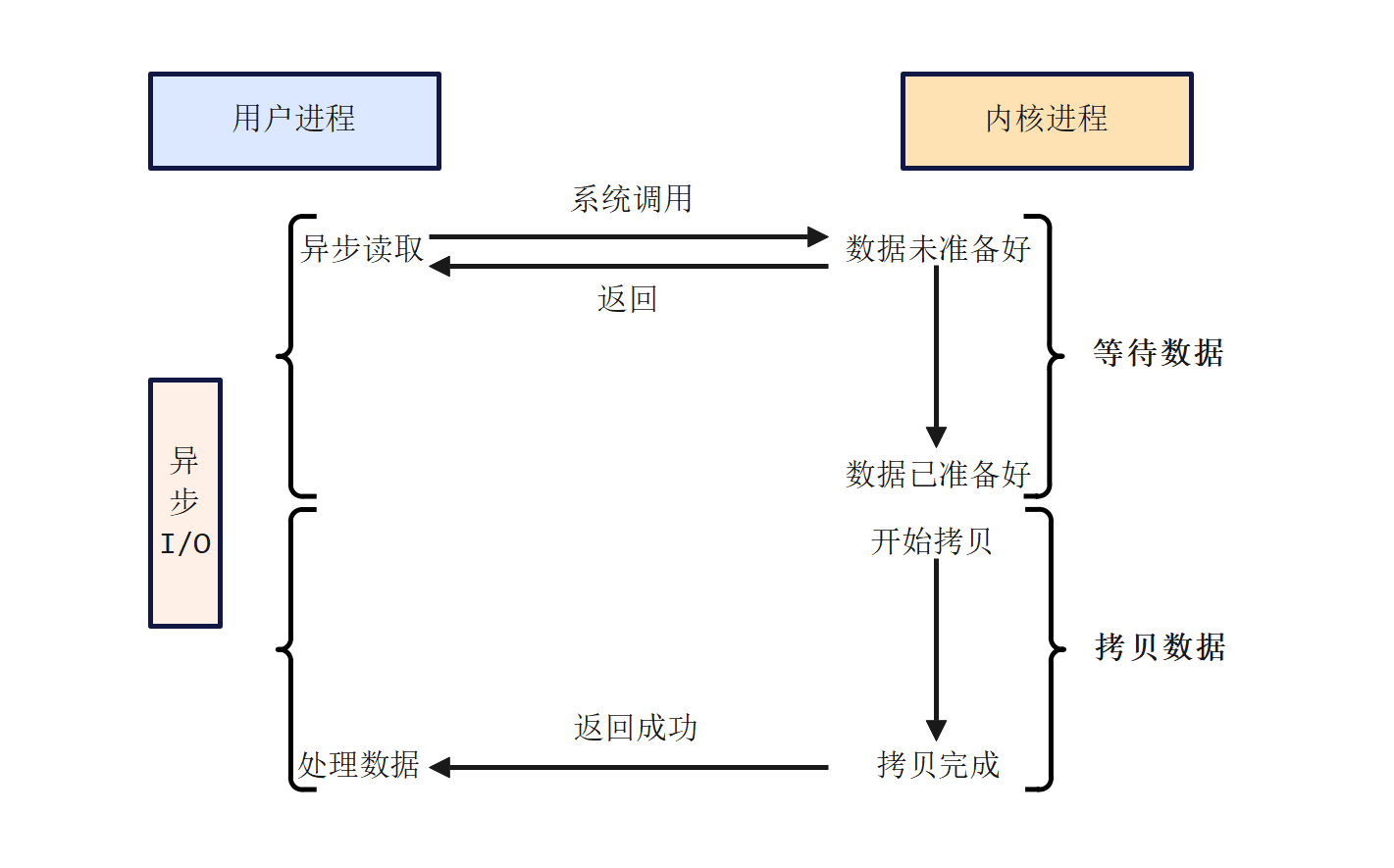
异步I/O(Asynchronous I/O)是一种更为先进的I/O模型,它允许进程发起一个I/O操作后,立即返回并不阻塞,同时不需要进程轮询或注册信号处理函数来检查I/O操作的状态。相反,当I/O操作完成后,内核会直接通知进程,并传递操作的结果。这种模型将I/O操作的等待和数据拷贝的工作完全交给了内核来处理,从而极大地提高了程序的并发性和响应性能。
异步I/O模型的特点包括:
- 非阻塞:进程在发起I/O操作后不会阻塞,可以继续执行其他任务,提高了并发性和响应性能。
- 数据一步到位:当I/O操作完成时,内核会将结果直接传递给进程,无需进程再次调用读取或写入操作。这减少了不必要的系统调用和上下文切换。
- Proactor模式:异步I/O通常与Proactor模式一起使用,该模式将I/O操作的完成通知和结果处理逻辑分离,使得代码更加清晰和易于管理。
- 底层支持:异步I/O需要操作系统的底层支持。在Linux中,异步I/O的支持从2.5版本内核开始引入,并在2.6版本内核中成为标准特性。因此,不是所有的操作系统都支持异步I/O。
- 实现和开发难度大:由于异步I/O模型的复杂性和对底层系统的依赖,实现和开发异步I/O应用程序通常比传统的阻塞式或非阻塞式I/O更加困难。
- 适合高性能高并发应用:异步I/O模型非常适合需要处理大量并发连接和高性能I/O操作的应用场景,如高性能服务器、数据库和分布式系统等。
需要注意的是,尽管异步I/O模型具有许多优点,但它并不总是最佳选择。在某些场景下,如并发量较小或I/O操作较为简单时,使用其他I/O模型可能更为合适。因此,在选择使用异步I/O模型时,需要根据具体的应用需求和场景来评估其适用性和性能优势。
五、I/O多路复用

I/O复用模型是一种允许单个进程同时等待多个I/O操作完成的机制。在Linux中,常见的I/O复用技术有select、poll和epoll。这些技术允许程序同时监听多个文件描述符(sockets、pipes、files等)的读写状态,从而在一个单独的线程中管理多个并发连接。
I/O复用模型的主要优势在于它减少了进程或线程的数量,从而降低了系统开销。通过复用单个进程或线程来处理多个I/O操作,可以避免为每个连接创建一个新的进程或线程所带来的资源消耗。此外,I/O复用还使得程序能够更加高效地利用CPU资源,因为它避免了阻塞和轮询的开销。
select、poll和epoll之间的主要区别在于它们的性能和功能。select是最早的I/O复用技术,但它有一个限制,即它能够监视的文件描述符数量是有限的(通常是1024)。poll解决了select的这个限制,允许监视更多的文件描述符,但它仍然使用轮询的方式来检查文件描述符的状态,这在大量并发连接时可能会导致性能下降。epoll是Linux特有的机制,它使用了基于事件通知的方式,而不是轮询,从而在大规模并发连接时提供了更高的性能。
在I/O复用模型中,数据仍然会先被拷贝到操作系统的页缓存中。但是,通过使用select、poll或epoll,程序可以在单个线程中同时等待多个文件描述符的I/O操作完成,从而避免了为每个I/O操作创建一个新线程的开销。当某个文件描述符的I/O操作完成时,相应的回调函数或事件处理函数会被触发,程序可以在这个函数中读取或写入数据,并将其从内核空间拷贝到用户空间。
需要注意的是,虽然I/O复用模型可以减少进程或线程的数量,但它并不能完全消除内核和用户空间之间的数据拷贝。在某些情况下,为了进一步提高性能,可以使用直接I/O(DIO)或零拷贝(Zero-Copy)机制来减少或消除这种拷贝。然而,这些机制通常需要在硬件和操作系统层面进行支持,并且可能不适用于所有类型的I/O操作。